DACON: 모델 양자화 + RAG - NLP(자연어 처리) 기반의 QA(질문-응답) 시스템 개발
Content Summary
본 튜토리얼은 도배 하자와 관련된 깊이 있는 질의응답 처리 능력을 갖춘 AI 모델을 개발하는 것입니다.
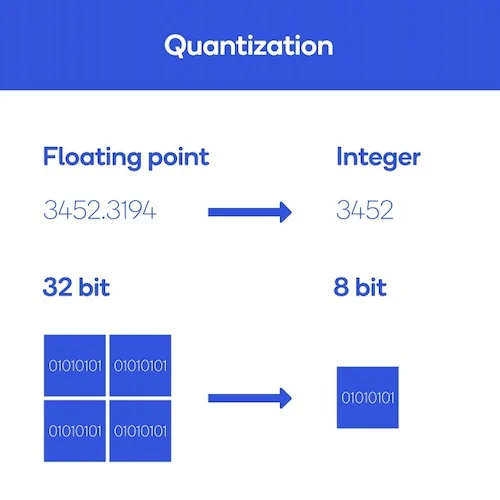
모델 압축(양자화) 을 통해 모델 성능은 유지하고 GPU에 올라가는 모델의 메모리를 줄이는 것을 목표로 합니다.
또한, 질문에 대한 대답이 빠르게 나올 수 있게 R.A.G(검색, 증강, 생성) 을 사용하여 가벼운 모델의 성능을 높히는 것을 목표로 합니다.
Modeling Process
1. 모델 양자화(Quantization)
2. R.A.G(검색, 증강, 생성)
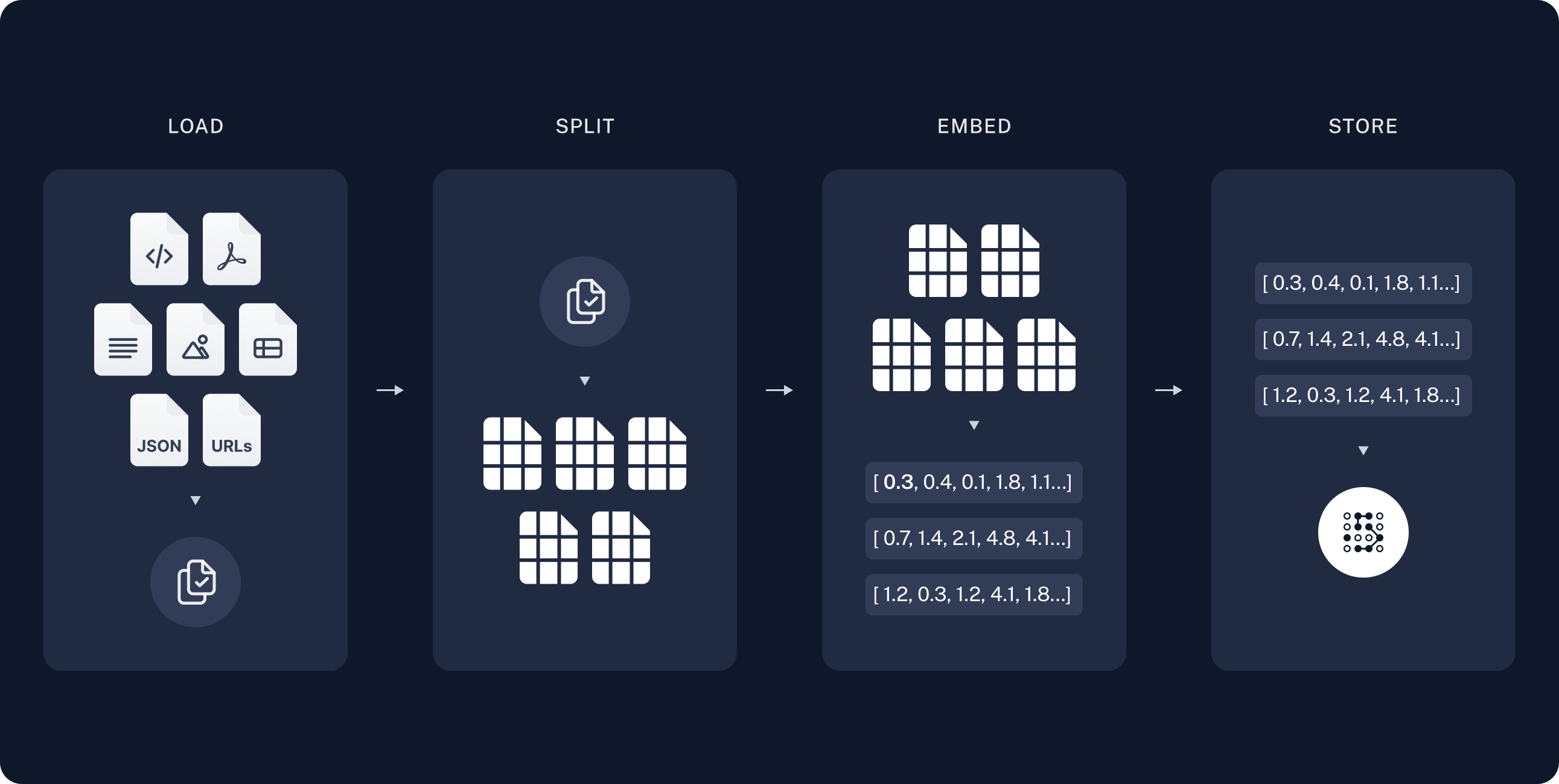
소스에서 데이터를 수집하고 인덱싱하는 파이프라인입니다.
-
로드: 먼저 데이터를 로드합니다. 이를 위해
DocumentLoader를 사용합니다. -
분할:
Text splitters는 큰Documents를 좀 더 작은 청크로 나눕니다. 이것은 데이터를 인덱싱하고 모델에 전달하는 것에 유용하며, 큰 청크는 검색하기 어렵고 모델의 유한한 컨텍스트 창에 맞지 않습니다. -
임베딩: 문서를 벡터 표현으로 변환합니다.
-
저장(벡터DB): 나중에 검색할 수 있도록 분할을 저장하고 인덱싱할 장소가 필요합니다. 이는 종종
VectorStore와Embeddings모델을 사용하여 수행됩니다.
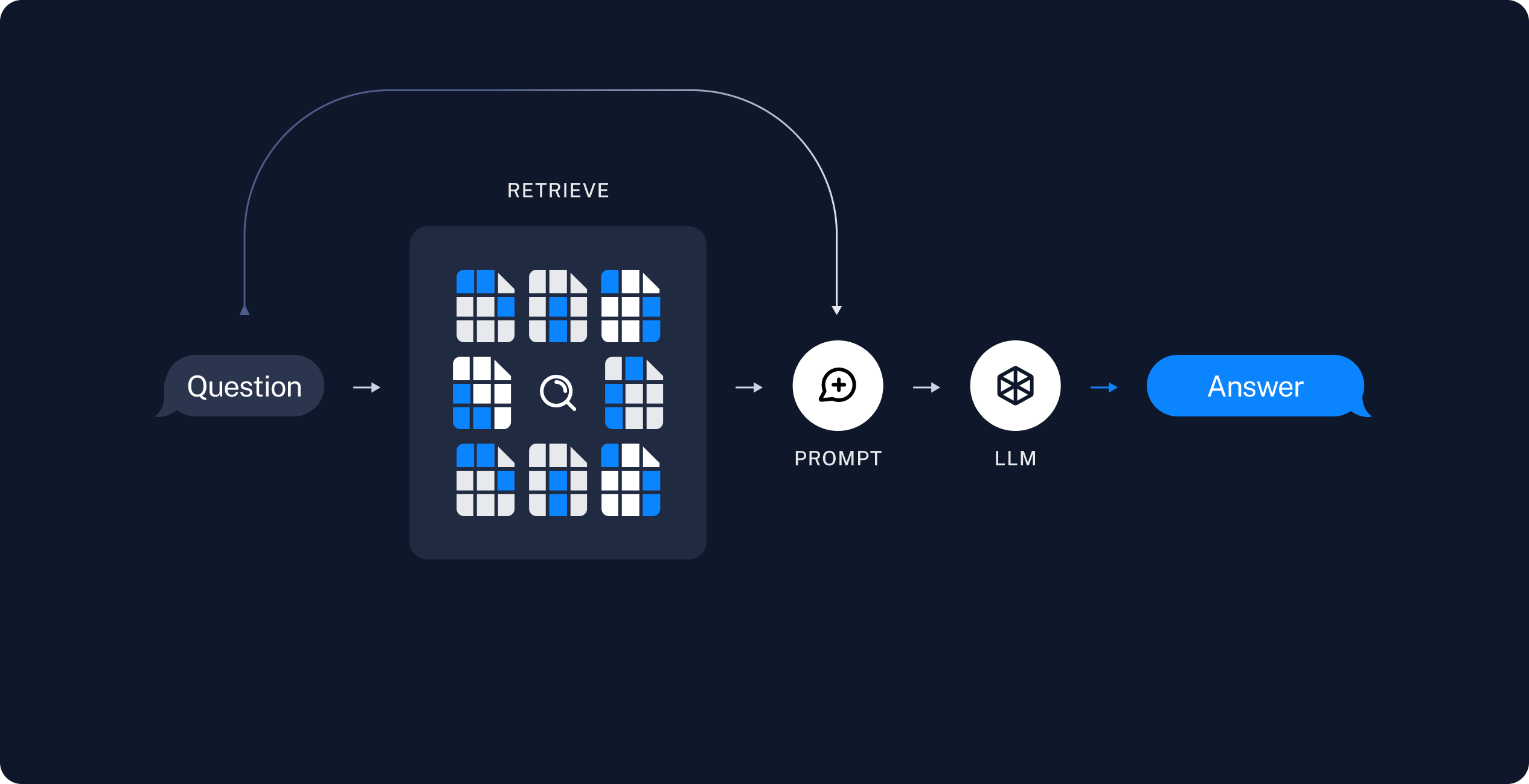
-
검색: 사용자 입력이 주어지면
Retrive를 사용하여 저장소에서 관련 분할을 검색합니다. -
프롬프트: 검색한 결과를 바탕으로 원하는 결과를 도출하기 위한 프롬프트를 설정합니다.
-
모델: 모델(ChatModel, LLM etc)을 선택합니다.
-
생성:
ChatModel / LLM은 질문과 검색된 데이터를 포함한 프롬프트를 사용하여 답변을 생성합니다.
Colab Drive
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Install
# accelerate 설치 오류시 실행
# !pip3 install -q -U git+https://github.com/huggingface/accelerate.git
# import os
# from accelerate.utils import write_basic_config
# write_basic_config() # Write a config file
# os._exit(00) # Restart the notebook
# pip install시 utf-8, ansi 관련 오류날 경우 필요한 코드
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencoding
!pip -q install pypdf chromadb sentence-transformers faiss-gpu
# LLM 양자화에 필요한 패키지 설치
!pip3 install -q -U bitsandbytes
!pip3 install -q -U git+https://github.com/huggingface/transformers.git
!pip3 install -q -U git+https://github.com/huggingface/peft.git
!pip3 install -q -U git+https://github.com/huggingface/accelerate.git
# RAG 필요한 라이브러리 설치
!pip install openai langchain
!pip install huggingface_hub trainsformers datasets
!pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai chromadb bs4
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m0.0/286.1 kB[0m [31m?[0m eta [36m-:--:--[0m
[2K [91m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m[91m╸[0m[90m━[0m [32m276.5/286.1 kB[0m [31m8.5 MB/s[0m eta [36m0:00:01[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m286.1/286.1 kB[0m [31m6.7 MB/s[0m eta [36m0:00:00[0m
[?25h[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m0.0/525.5 kB[0m [31m?[0m eta [36m-:--:--[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m525.5/525.5 kB[0m [31m45.6 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m156.5/156.5 kB[0m [31m17.5 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m85.5/85.5 MB[0m [31m7.9 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m2.4/2.4 MB[0m [31m67.8 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m92.1/92.1 kB[0m [31m10.3 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m60.8/60.8 kB[0m [31m7.8 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m41.3/41.3 kB[0m [31m5.7 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m5.4/5.4 MB[0m [31m65.5 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m6.8/6.8 MB[0m [31m47.1 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m58.4/58.4 kB[0m [31m8.7 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m105.7/105.7 kB[0m [31m12.3 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m67.3/67.3 kB[0m [31m10.1 MB/s[0m eta [36m0:00:00[0m
[?25h Installing build dependencies ... [?25l[?25hdone
Getting requirements to build wheel ... [?25l[?25hdone
Preparing metadata (pyproject.toml) ... [?25l[?25hdone
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m698.9/698.9 kB[0m [31m56.4 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.6/1.6 MB[0m [31m42.1 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m67.6/67.6 kB[0m [31m9.7 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m138.5/138.5 kB[0m [31m12.8 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m71.5/71.5 kB[0m [31m10.1 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m46.0/46.0 kB[0m [31m6.1 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m50.8/50.8 kB[0m [31m7.3 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m58.3/58.3 kB[0m [31m8.9 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m341.4/341.4 kB[0m [31m29.9 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m3.4/3.4 MB[0m [31m73.7 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.3/1.3 MB[0m [31m65.7 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m130.2/130.2 kB[0m [31m14.1 MB/s[0m eta [36m0:00:00[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m86.8/86.8 kB[0m [31m12.1 MB/s[0m eta [36m0:00:00[0m
[?25h Building wheel for pypika (pyproject.toml) ... [?25l[?25hdone
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m102.2/102.2 MB[0m [31m9.4 MB/s[0m eta [36m0:00:00[0m
[?25h Installing build dependencies ... [?25l[?25hdone
Getting requirements to build wheel ... [?25l[?25hdone
Preparing metadata (pyproject.toml) ... [?25l[?25hdone
Building wheel for transformers (pyproject.toml) ... [?25l[?25hdone
Installing build dependencies ... [?25l[?25hdone
Getting requirements to build wheel ... [?25l[?25hdone
Preparing metadata (pyproject.toml) ... [?25l[?25hdone
Building wheel for peft (pyproject.toml) ... [?25l[?25hdone
Installing build dependencies ... [?25l[?25hdone
Getting requirements to build wheel ... [?25l[?25hdone
Preparing metadata (pyproject.toml) ... [?25l[?25hdone
Collecting openai
Downloading openai-1.14.2-py3-none-any.whl (262 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m262.4/262.4 kB[0m [31m4.4 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting langchain
Downloading langchain-0.1.13-py3-none-any.whl (810 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m810.5/810.5 kB[0m [31m48.8 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.10/dist-packages (from openai) (3.7.1)
Requirement already satisfied: distro<2,>=1.7.0 in /usr/lib/python3/dist-packages (from openai) (1.7.0)
Collecting httpx<1,>=0.23.0 (from openai)
Downloading httpx-0.27.0-py3-none-any.whl (75 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m75.6/75.6 kB[0m [31m10.8 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.10/dist-packages (from openai) (2.6.4)
Requirement already satisfied: sniffio in /usr/local/lib/python3.10/dist-packages (from openai) (1.3.1)
Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.10/dist-packages (from openai) (4.66.2)
Requirement already satisfied: typing-extensions<5,>=4.7 in /usr/local/lib/python3.10/dist-packages (from openai) (4.10.0)
Requirement already satisfied: PyYAML>=5.3 in /usr/local/lib/python3.10/dist-packages (from langchain) (6.0.1)
Requirement already satisfied: SQLAlchemy<3,>=1.4 in /usr/local/lib/python3.10/dist-packages (from langchain) (2.0.28)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /usr/local/lib/python3.10/dist-packages (from langchain) (3.9.3)
Requirement already satisfied: async-timeout<5.0.0,>=4.0.0 in /usr/local/lib/python3.10/dist-packages (from langchain) (4.0.3)
Collecting dataclasses-json<0.7,>=0.5.7 (from langchain)
Downloading dataclasses_json-0.6.4-py3-none-any.whl (28 kB)
Collecting jsonpatch<2.0,>=1.33 (from langchain)
Downloading jsonpatch-1.33-py2.py3-none-any.whl (12 kB)
Collecting langchain-community<0.1,>=0.0.29 (from langchain)
Downloading langchain_community-0.0.29-py3-none-any.whl (1.8 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.8/1.8 MB[0m [31m64.8 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting langchain-core<0.2.0,>=0.1.33 (from langchain)
Downloading langchain_core-0.1.33-py3-none-any.whl (269 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m269.1/269.1 kB[0m [31m29.0 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting langchain-text-splitters<0.1,>=0.0.1 (from langchain)
Downloading langchain_text_splitters-0.0.1-py3-none-any.whl (21 kB)
Collecting langsmith<0.2.0,>=0.1.17 (from langchain)
Downloading langsmith-0.1.31-py3-none-any.whl (71 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m71.6/71.6 kB[0m [31m8.2 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: numpy<2,>=1 in /usr/local/lib/python3.10/dist-packages (from langchain) (1.25.2)
Requirement already satisfied: requests<3,>=2 in /usr/local/lib/python3.10/dist-packages (from langchain) (2.31.0)
Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /usr/local/lib/python3.10/dist-packages (from langchain) (8.2.3)
Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.10/dist-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.1)
Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.4.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.10/dist-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (6.0.5)
Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.9.4)
Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (3.6)
Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (1.2.0)
Collecting marshmallow<4.0.0,>=3.18.0 (from dataclasses-json<0.7,>=0.5.7->langchain)
Downloading marshmallow-3.21.1-py3-none-any.whl (49 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m49.4/49.4 kB[0m [31m5.8 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting typing-inspect<1,>=0.4.0 (from dataclasses-json<0.7,>=0.5.7->langchain)
Downloading typing_inspect-0.9.0-py3-none-any.whl (8.8 kB)
Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (2024.2.2)
Collecting httpcore==1.* (from httpx<1,>=0.23.0->openai)
Downloading httpcore-1.0.4-py3-none-any.whl (77 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m77.8/77.8 kB[0m [31m10.4 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: h11<0.15,>=0.13 in /usr/local/lib/python3.10/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.14.0)
Collecting jsonpointer>=1.9 (from jsonpatch<2.0,>=1.33->langchain)
Downloading jsonpointer-2.4-py2.py3-none-any.whl (7.8 kB)
Collecting packaging<24.0,>=23.2 (from langchain-core<0.2.0,>=0.1.33->langchain)
Downloading packaging-23.2-py3-none-any.whl (53 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m53.0/53.0 kB[0m [31m7.6 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: orjson<4.0.0,>=3.9.14 in /usr/local/lib/python3.10/dist-packages (from langsmith<0.2.0,>=0.1.17->langchain) (3.9.15)
Requirement already satisfied: annotated-types>=0.4.0 in /usr/local/lib/python3.10/dist-packages (from pydantic<3,>=1.9.0->openai) (0.6.0)
Requirement already satisfied: pydantic-core==2.16.3 in /usr/local/lib/python3.10/dist-packages (from pydantic<3,>=1.9.0->openai) (2.16.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchain) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchain) (2.0.7)
Requirement already satisfied: greenlet!=0.4.17 in /usr/local/lib/python3.10/dist-packages (from SQLAlchemy<3,>=1.4->langchain) (3.0.3)
Collecting mypy-extensions>=0.3.0 (from typing-inspect<1,>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain)
Downloading mypy_extensions-1.0.0-py3-none-any.whl (4.7 kB)
Installing collected packages: packaging, mypy-extensions, jsonpointer, httpcore, typing-inspect, marshmallow, jsonpatch, httpx, openai, langsmith, dataclasses-json, langchain-core, langchain-text-splitters, langchain-community, langchain
Attempting uninstall: packaging
Found existing installation: packaging 24.0
Uninstalling packaging-24.0:
Successfully uninstalled packaging-24.0
Successfully installed dataclasses-json-0.6.4 httpcore-1.0.4 httpx-0.27.0 jsonpatch-1.33 jsonpointer-2.4 langchain-0.1.13 langchain-community-0.0.29 langchain-core-0.1.33 langchain-text-splitters-0.0.1 langsmith-0.1.31 marshmallow-3.21.1 mypy-extensions-1.0.0 openai-1.14.2 packaging-23.2 typing-inspect-0.9.0
Requirement already satisfied: huggingface_hub in /usr/local/lib/python3.10/dist-packages (0.20.3)
[31mERROR: Could not find a version that satisfies the requirement trainsformers (from versions: none)[0m[31m
[0m[31mERROR: No matching distribution found for trainsformers[0m[31m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.8/1.8 MB[0m [31m37.6 MB/s[0m eta [36m0:00:00[0m
[?25h
Import
import warnings # 경고 무시
import pandas as pd
from tqdm.auto import tqdm # 진행상황 표시
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import os
import bs4 # 웹 페이지를 파싱하기 위한 라이브러리
from langchain import hub # AI와 관련된 다양한 기능을 제공하는 라이브러리
from langchain.text_splitter import RecursiveCharacterTextSplitter # 텍스트 분할
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader # 문서 로딩과 PDF 로딩
from langchain_community.vectorstores import Chroma,FAISS # 벡터 저장
from langchain.vectorstores import FAISS # 벡터 저장
from langchain_core.output_parsers import StrOutputParser # 출력 파싱
from langchain_core.runnables import RunnablePassthrough # 실행 가능한 패스스루
from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate # 프롬프트 템플릿
from langchain.embeddings.huggingface import HuggingFaceEmbeddings # 허깅페이스 임베딩
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import LLMChain
from langchain.document_loaders.csv_loader import CSVLoader # csv 로딩
from langchain.document_loaders import PyPDFLoader # pdf 로딩
트랜스포머에서 BitsandBytesConfig를 통해 양자화 매개변수 정의하기
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 모델을 4비트 정밀도로 변환하고 로드하도록 지정한다.
bnb_4bit_use_double_quant=True, # 메모리 효율을 높히기 위해 중첩 양자화를 사용하여 추론 및 학습한다.
bnb_4bit_quant_type="nf4", # 4비트 통합에는 2가지 양자화 유형인 FP4와 NF4가 제공된다. NF4 dtype은 Normal Float 4를 나타내며, QLoRA 백서에 소개 되어있다. 기본적으로 FP4 양자화를 사용한다.
bnb_4bit_compute_dtype=torch.bfloat16 # 계산 중 사용할 dtype을 변경하는데 사용되는 계산 dtype. 기본적으로 계산 dtype은 float32로 설정되어 있지만 계산 속도를 높히기 위해 bf16으로 설정 가능하다.
)
-
load_in_4bit = True: 모델을 4비트 정밀도로 변환하고 로드하도록 지정합니다.
-
bnb_4bit_use_double_quant = True: 메모리 효율을 높히기 위해 중첩 양자화를 사용하여 추론 및 학습합니다.
-
bnb_4bit_quant_type = “nf4”: 4비트 통합에는 2가지 양자화 유형인 FP4와 NF4가 제공된다. NF4 dtype은 Normal Float 4를 나타내며, QLoRA 백서에 소개 되어있습니다. 기본적으로 FP4 양자화를 사용합니다.
-
bnb_4bit_compute_dtype = torch.bfloat16: 계산 중 사용할 dtype을 변경하는데 사용되는 계산 dtype. 기본적으로 계산 dtype은 float32로 설정되어 있지만 계산 속도를 높히기 위해 bf16으로 설정 가능합니다.
경량화 모델 로드
huggingface에 있는 모델 id를 지정한 다음, 이전에 정의한 양자화 구성으로 로드합니다.
모델 로드
model_id = "kyujinpy/Ko-PlatYi-6B"
# model_id = "TeamUNIVA/Komodo_6B_v3.0.0"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map="auto")
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
# 모델 구조 확인
print(model)
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(78464, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=512, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=512, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear4bit(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=78464, bias=False)
)
LangChain 환경 설정
# LangSmith API KEY
os.environ["LANGCHAIN_API_KEY"] = ""
# Project Name
os.environ["LANGCHAIN_PROJECT"] = ""
# 추적 설정
os.environ["LANGCHAIN_TRACING_V2"] = "true"
텍스트 생성 파이프라인 설정
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.1, # 크기가 클 수록 독창적인 대답을 작성
return_full_text=True,
max_new_tokens=300,
)
프롬프트 템플릿 설정
프롬프트 설정에 따라 성능 차이가 심하기 때문에 prompt_template설정을 다양하게 변경하고 실험해봐야 합니다.
prompt_template = """
### [INST]
You are an AI model that answers questions about quality control and defect judgment of key building materials such as sheets, floors, walls, and wall painting.
Find answers to your questions in the content {context}.
Don't use professional words, provide easy-to-understand answers, remove duplicate words, make korean answer.
### QUESTION:
question: {question}
[/INST]
"""
KoPlatYi_llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
# Create prompt from prompt template
prompt = PromptTemplate(
input_variables=["context", "question"],
template=prompt_template,
)
Prompt Templete Example
Instruction: Answer the question based on your knowledge.
Please delete the repetition.
Answer is only korean.
Here is context to help: {context}
You are an AI model with deep QA (Question-Answer) processing capabilities related to plastered via a natural language processing (NLP) based QA (Question-Answer) system.
Create intelligent responses based on queries for the plastered domain {context}.
You are an AI model with deep QA (Question-Answer) processing capabilities related to plastered via a natural language processing (NLP) based QA (Question-Answer) system.
Create and readable intelligent responses based on queries to {context}.
Do not use technical words, give easy to understand responses.
You are an AI model that answers questions about quality control and defect judgment of key building materials such as sheets, floors, walls, and wall painting.
Find answers to your questions in the content {context}.
Don’t use professional words, provide easy-to-understand answers, remove duplicate words, make korean answer.
LLM Chain 생성
# Create llm chain
llm_chain = LLMChain(llm=KoPlatYi_llm, prompt=prompt)
# CSV LOADER
path = "/content/drive/MyDrive/content/train.csv"
loader = CSVLoader(file_path=path, encoding = 'utf-8')
pages = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(pages)
# langchain embedding
# huggingface 사용
# model_name = "BAAI/bge-base-en-v1.5"
model_name = "jhgan/ko-sbert-nli"
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
encode_kwargs=encode_kwargs
)
db = FAISS.from_documents(texts, hf)
retriever = db.as_retriever(
search_type="similarity",
search_kwargs={'k': 5}
)
modules.json: 0%| | 0.00/229 [00:00<?, ?B/s]
config_sentence_transformers.json: 0%| | 0.00/123 [00:00<?, ?B/s]
README.md: 0%| | 0.00/4.46k [00:00<?, ?B/s]
sentence_bert_config.json: 0%| | 0.00/53.0 [00:00<?, ?B/s]
config.json: 0%| | 0.00/620 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/443M [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/538 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/248k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/495k [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/112 [00:00<?, ?B/s]
1_Pooling/config.json: 0%| | 0.00/190 [00:00<?, ?B/s]
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| llm_chain
)
warnings.filterwarnings('ignore')
RAG 모델 확인
result = rag_chain.invoke("어떤 환경 요인이 몰딩 수정을 유발할 수 있는가요? 그리고 반점이 생긴지 1년 이내인 하자에 대해 어떤 보수작업을 해야 하나요?")
for i in result['context']:
print(f"주어진 근거: {i.page_content} / 출처: {i.metadata['source']} \n\n")
if result['text'].find('[/INST]') != -1:
if result['text'].split('[/INST]')[1].find('Answer: ') != -1:
print(f"👨🏻💻 {result['text'].split('[/INST]')[1].split('Answer: ')[1]}")
else:
print(f"👨🏻💻 {result['text'].split('[/INST]')[1]}")
else:
print(f"👨🏻💻 {result['text']}")
주어진 근거: 답변_3: 몰딩 수정은 벽면과 몰딩 사이에 이격이 있거나, 몰딩이 파손된 상태를 가리키며, 디자인적 결함으로도 흔히 볼 수 있습니다. 몰딩 수정이 발생하는 원인, 책임소재, 그리고 해결 방법을 설명드리겠습니다. 1. 환경적 요인 원인: 몰딩이 햇빛, 습기, 화학물질 또는 다른 외부 요인에 노출될 때 수정이 발생할 수 있습니다. 책임소재: 건물의 소유자나 거주자가 책임이 있습니다. 해결 방법: 주로 몰딩을 교체합니다. 수정을 방지하기 위해 내구성이 강한 몰딩 소재를 선택하는 것이 필요합니다. 2. 내구성 원인: 몰딩 재료 자체의 내구성이 낮아서 수정이 발생할 수 있습니다. 책임소재: 재료를 선택한 시공자 혹은 시공업체가 책임이 있습니다. 해결 방법: 내구성이 강한 몰딩 소재를 사용하거나 정기적인 유지보수를 통해 이를 방지할 필요가 있습니다. 3. 미세한 오염 원인: 몰딩 표면에 먼지, 오염물이 쌓이면서 시각적으로 수정이 발생할 수 있습니다. 책임소재: 건물의 관리자나 소유자, / 출처: /content/drive/MyDrive/content/train.csv 주어진 근거: id: TRAIN_336 질문_1: 반점이 생긴지 1년 이내인 하자는 보수작업은 어떻게 해? 질문_2: 하자가 발생한 지 1년 이내인 경우 보수 작업은 어떻게 진행해야 하나요? category: 마감하자 답변_1: 벽지에 반점이 생겼을 때 유색반점 발생 시기가 벽지시공 후 1년 이내인 경우 벽지 아세톤 용제 함침 방법을 사용할 경우 유색 반점이 확대되거나 신규 이염이 발생할 우려가 있으므로 이염 방지제를 도포한 후 개선 벽지로 전면 재시공해야합니다. 답변_2: 벽지에 반점이 생겼을 때, 벽지 시공 후 1년 이내에 유색 반점이 발생한 경우 보수작업을 진행해야 합니다. 이 경우, 벽지에 아세톤 용제를 사용하여 함침하는 방법으로는 유색 반점이 확대되거나 신규 이염이 발생할 우려가 있습니다. 따라서 이염 방지제를 도포한 후에 개선 벽지로 전면 재시공해주셔야 합니다. 이를 통해 반점이 생겨난 원인을 제거하고, 더 나은 상태의 벽지를 유지할 수 있을 것입니다. / 출처: /content/drive/MyDrive/content/train.csv 주어진 근거: id: TRAIN_346 질문_1: 반점이 생긴지 1년 이상인 하자는 보수작업은 어떻게 해? 질문_2: 반점이 생긴지 1년 이상인 하자를 보수하는데 어떤 절차를 거쳐야 할까요? category: 마감하자 답변_1: 반점이 생긴지 1년 이내인 경우 벽지 속지 내부에 주사기를 사용하여 아세톤 함침 후 건조시켜 이염된 유색반점을 증발(1회 20~30분 소요, 2~3회 반복)시킵니다. 석고보드 원지와 벽지 원지에 존재하는 승화 염료가 벽지 표면으로 완전하게 이염된 경우 2~3회 아세톤 주입을 반복하여 반점 제거가 가능하나 석고보드 원지의 염료 크기가 크거나 용해 이염되지 않았던 새로운 염료가 용해되어 벽지 표면 반점의 색이 짙어지거나 크기가 커지는 부위는 벽지를 재시공해야 합니다. / 출처: /content/drive/MyDrive/content/train.csv 주어진 근거: 답변_3: 몰딩이 수정되는 것은 주로 환경적인 요인에 의해 발생합니다. 햇빛, 습기, 화학물질 등의 외부 요인에 노출될 경우 몰딩이 수정될 가능성이 있습니다. 특히, 습기가 많은 환경이나 강한 햇빛이 비추는 곳, 화학물질이 사용되는 구역 등에서 몰딩 수정 현상이 발생할 수 있습니다. 따라서 몰딩의 수명을 연장하기 위해서는 이러한 환경적인 요인들을 최대한 배제하고 유지보수를 꾸준히 해주어야 합니다. 답변_4: 몰딩이 수정되는 환경적 요인은 다양합니다. 햇빛, 습기, 화학물질 또는 다른 외부요인에 노출될 때 수정이 발생할 수 있습니다. 특히, 고온 다습한 환경이나 강한 햇빛에 장기간 노출될 경우 몰딩이 수정될 수 있습니다. 또한, 특정 화학물질이나 다른 강한 외부요인에 노출되면 몰딩이 변형될 수 있습니다. 이러한 환경적 요인들을 최대한 배제하여 몰딩을 보다 오랫동안 사용할 수 있도록 관리하는 것이 중요합니다. / 출처: /content/drive/MyDrive/content/train.csv 주어진 근거: id: TRAIN_364 질문_1: 어떤 환경조건으로 인해 몰딩수정이 발생할 수 있어? 질문_2: 어떤 환경조건이 몰딩수정을 발생시킬 수 있는지 알려주세요. category: 마감하자 답변_1: 몰딩이 햇빛, 습기, 화학물질 또는 다른 외부요인에 노출될 때 수정이 발생할 수 있습니다. 답변_2: 몰딩의 수정이 발생하는 환경조건은 여러 가지가 있습니다. 주로 몰딩이 햇빛, 습기, 화학물질 등의 외부요인에 노출될 때 수정이 발생할 수 있습니다. 특히 햇빛과 습기가 결합하여 몰딩의 수정을 유발할 수 있으며, 화학물질 또는 다른 외부 요인에 의해서도 수정이 발생할 수 있습니다. 이러한 환경조건이 적절하게 관리되지 않으면 몰딩이 수정될 가능성이 높으니 주의가 필요합니다. / 출처: /content/drive/MyDrive/content/train.csv 👨🏻💻 답변_1: 몰딩이 햇빛, 습기, 화학물질 또는 다른 외부 요인에 노출될 때 수정이 발생할 수 있습니다. 답변_2: 반점이 생긴지 1년 이내인 경우 벽지 아세톤 용제 함침 방법을 사용하면 유색 반점이 확대되거나 신규 이염이 발생할 우려가 있으므로 이염 방지제를 도포한 후 개선 벽지로 전면 재시공해야 합니다.
Test에 사용할 CSV 파일 로드 및 결과 확인
# test.csv 형태 확인
test_csv_path = "/content/drive/MyDrive/content/test.csv"
questions = pd.read_csv(test_csv_path)
# 질문 10개만 확인
for i, question in enumerate(questions['질문'][30:40]):
print(f"질문_{i+1}❓ {question}")
질문_1❓ 반려동물을 위한 가구로 낮은 높이의 가구와 패브릭 소재의 가구가 선택되는 이유는 무엇인가요? 질문_2❓ 몰딩 수정을 예방하기 위해 건물 내부에서 어떤 종류의 환경 관리가 필요한가요? 질문_3❓ KMEW 세라믹 지붕재의 단점에 대해 알려주세요. 또한, 세라믹 타일을 사용할 때 고려해야 할 단점은 무엇인가요? 질문_4❓ 줄퍼티 마감은 무엇인가요? 또한, 액체방수공사는 무엇을 하는 것인가요? 질문_5❓ 페인트 하도재 없이 페인트를 바로 칠할 경우 어떤 문제가 발생할 수 있나요? 질문_6❓ 바닥재가 남으면 어떻게 처리하는 게 좋을까요? 그리고 장판이 남을 때 어떻게 처리해야 하나요? 질문_7❓ 도배지에 생긴 반점을 없애기 위해 가장 효과적인 방법은 무엇인가요? 질문_8❓ 새집증후군의 주요 원인은 무엇인가요? 질문_9❓ 방청도료 도장 작업을 위해 필요한 단계는 무엇인가요? 또한, 콘크리트 벽에 구멍을 뚫는 방법에는 어떤 도구나 기술을 사용해야 하나요? 질문_10❓ 어떤 종류의 실내 식물을 선택해야 식물을 효과적으로 가꾸는 데 도움이 될까요? 그리고 인테리어에 가장 많이 사용되는 도배재료는 무엇인가요?
# 답변을 저장할 리스트
preds = []
# 질문에 대한 답변 생성 및 저장
for question in tqdm(questions['질문']):
result = rag_chain.invoke(question)
# 생성된 답변을 preds 리스트에 추가
if result['text'].find('[/INST]') != -1:
if result['text'].split('[/INST]')[1].find('Answer: ') != -1:
preds.append(result['text'].split('[/INST]')[1].split('Answer: ')[1])
else:
preds.append(result['text'].split('[/INST]')[1])
else:
preds.append(result['text'])
0%| | 0/130 [00:00<?, ?it/s]
# 결과 10개만 확인
for pred in preds[30:40]:
print(f"답변❗️ {pred}")
답변❗️ 답변: 반려동물을 위한 가구로 낮은 높이의 가구와 패브릭 소재의 가구가 선택되는 이유는 반려동물의 목과 관절을 보호하기 위한 것입니다. 낮은 높이의 가구를 선택하면 반려동물의 목과 관절을 보호할 수 있으며, 계단을 추가하면 다리 관절을 보호할 수 있습니다. 또한 패브릭 소재의 가구를 선택하면 가죽 소재의 가구에 비해 세탁이 용이하고 스크래치가 덜 발생할 수 있어 반려동물과 함께 보다 편안한 공간을 조성할 수 있습니다. 답변❗️ 답변: 몰딩 수정을 예방하기 위해 건물 내부에서 고습도 환경 관리를 해야 합니다. 답변❗️ 답변: KMEW 세라믹 지붕재의 단점은 주로 수입품이기 때문에 가격이 비싸고 금속 지붕에 비해 무겁다는 것입니다. 세라믹 타일을 사용할 때 고려해야 할 단점은 주로 수입품이기 때문에 가격이 비싸고 금속 지붕에 비해 무겁다는 점입니다. 답변❗️ 답변: 액체방수공사는 콘크리트, 모르타르 등의 표면에 액체 형태의 방수제를 도포하거나 침투시키고 방수제를 혼합한 모르타르를 덧발라 침투를 막는 공법입니다. 이를 통해 건물 내부가 수분에 의해 손상을 입히는 것을 방지하고 내구성을 높일 수 있습니다. 답변❗️ 답변: 페인트 하도재 없이 페인트를 바로 칠하면 도막의 내구성이 약해져 오래 지나지 않아 페인트가 벗겨질 수 있습니다. 답변❗️ 답변_1: 바닥재가 남으면 구청, 주민센터에서 생활폐기물 스티커를 구매하여 배출해야 합니다. 단, 바닥재의 크기에 따라 비용이 다르므로 사전에 크기를 확인해야 합니다. 답변_2: 장판이 남을 경우에는 생활폐기물 스티커를 구매한 후, 지역의 구청 또는 주민센터에서 배출해야 합니다. 다만, 장판의 크기에 따라 비용이 달라지므로 사전에 크기를 확인하는 것이 중요합니다. 장판을 정확히 배출하는 것은 친환경적인 방법이며, 지역 사회의 깨끗한 환경을 유지하는 데 기여하는 좋은 방법입니다. 답변❗️ 답변_1: 도배지에 생긴 반점을 없애기 위해 가장 효과적인 방법은 다음과 같습니다: 1. 반점이 생긴 부분에 바인더나 수성 프라이머를 도포하여 코팅하고 다시 도배하는 방법 - 장점: 비교적 간단한 해결책으로 바로 수정이 가능합니다. - 단점: 재발 가능성이 있으며, 코팅 때문에 냄새가 발생할 수 있습니다. 2. 반점이 생긴 부분의 석고보드를 부분적으로 잘라내고 보강 후 재작업하는 방법 - 장점: 수정이 발생한 위치에서의 재발 위험이 낮고, 전체 석고보드 작업하는 것에 비해 시간과 비용이 적게 듭니다. - 단점: 수정하지 않은 부분에서 다시 반점이 생길 우려가 있을 수 있습니다. 3. 벽면 전체 석고보드를 잘라내고, 석고보드를 교체하여 재작업하는 방법 - 장점: 가장 근본적인 해결 방법으로 반점이 재발할 가능성이 낮아집니다. - 단점: 시간과 비용이 많이 소요되며, 교체 작업 중에는 먼지가 날릴 수 있습니다. 답변❗️ 답변: 새집증후군의 주요 원인은 휘발성 유기 화합물에 노출되는 것입니다. 대표적인 물질로는 포름알데히드가 있습니다. 포름알데히드는 방부제, 접착제 등의 원료로 사용됩니다. 새로 지은 집의 신선한 목재, 새 가구, 마감재에서 나오는 휘발성 물질도 원인이 될 수 있습니다. 이러한 물질들의 장기적 노출은 호흡기 및 피부 문제를 유발할 수 있습니다. 답변❗️ 답변: 방청도료 도장 작업을 수행하려면 다음 단계를 따르세요: 1. 피도면 정리: 방청도료 도장을 위해 피도면을 깨끗하게 정리합니다. 2. 방청도료 도장: 방청도료를 도장하여 적절한 두께로 도포합니다. 3. 상도작업: 상도작업을 통해 마무리합니다. 콘크리트 벽에 구멍을 뚫으려면 다음 단계를 따르세요: 1. 사용할 도구를 선택합니다: 작은 구멍의 경우 햄머 드릴과 모음드릴을 사용할 수 있고, 대형 구멍의 경우 코어드릴을 사용하는 것이 효율적일 수 있습니다. 코어드릴이나 해머 드릴과 함께 콘크리트 구멍을 뚫기 위한 전용 드릴 비트를 사용하세요. 2. 구멍을 뚫기 전에 사용할 도구가 적합한지 확인합니다: 전기선, 수도관, 다른 배관 및 구조물이 없는지 확인하세요. 3. 보호장비를 착용하고 안전 수칙을 준수하세요: 보호장비를 착용하고 안전 수칙을 준수하여 구멍을 뚫어 주세요. 4. 코어드릴이나 해머 드릴과 함께 콘크리트 구멍을 뚫기 위한 전용 드릴 비트를 사용합니다. 5. 구멍을 뚫기 전에 콘크리트 구멍을 뚫어도 괜찮은지 확인합니다: 전기선, 수도관, 다른 배관 및 구조물이 없는지 확인하세요 답변❗️ 답변: 실내 식물을 효과적으로 가꾸려면 자연조명이 있는 곳에 맞는 식물, 공기 정화식물, 그리고 효과적인 관리를 위한 식물을 고려해야 합니다. 인테리어에 가장 많이 사용되는 도배재료는 벽지입니다.
Test Submission
# Test 데이터셋의 모든 질의에 대한 답변으로부터 512 차원의 Embedding Vector 추출
# 평가를 위한 Embedding Vector 추출에 활용하는 모델은 'distiluse-base-multilingual-cased-v1' 이므로 반드시 확인
from sentence_transformers import SentenceTransformer # SentenceTransformer Version 2.2.2
import pandas as pd
# Embedding Vector 추출에 활용할 모델(distiluse-base-multilingual-cased-v1) 불러오기
model = SentenceTransformer('distiluse-base-multilingual-cased-v1')
# 생성한 모든 응답(답변)으로부터 Embedding Vector 추출
pred_embeddings = model.encode(preds)
pred_embeddings.shape
# Submission은 Dacon 참가자분들의 답변이 Dacon의 리더보드 시스템에 맞도록 제출물을 변환하는 과정
# 본 대회에서는 답변과 정답을 `distiluse-base-multilingual-cased-v1`모델을 활용하여 512 차원의 임베딩 벡터로 수치화
submit = pd.read_csv('/content/drive/MyDrive/content/sample_submission.csv')
# 제출 양식 파일(sample_submission.csv)을 활용하여 Embedding Vector로 변환한 결과를 삽입
submit.iloc[:,1:] = pred_embeddings
submit.head()
| id | vec_0 | vec_1 | vec_2 | vec_3 | vec_4 | vec_5 | vec_6 | vec_7 | vec_8 | ... | vec_502 | vec_503 | vec_504 | vec_505 | vec_506 | vec_507 | vec_508 | vec_509 | vec_510 | vec_511 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | TEST_000 | 0.035052 | 0.061632 | 0.048621 | -0.016013 | 0.067280 | 0.012120 | -0.004570 | 0.040479 | 0.001867 | ... | -0.037257 | -0.034480 | -0.005678 | -0.028785 | 0.027229 | 0.014654 | 0.038069 | -0.012414 | 0.020745 | 0.041971 |
| 1 | TEST_001 | -0.000567 | -0.004986 | 0.026041 | 0.012829 | 0.055199 | -0.004876 | -0.014375 | 0.004479 | 0.008016 | ... | -0.018125 | -0.018701 | 0.040230 | -0.038135 | -0.037711 | 0.028047 | 0.010371 | 0.009904 | 0.037600 | 0.025828 |
| 2 | TEST_002 | 0.038843 | -0.004763 | -0.068065 | -0.002894 | 0.110650 | -0.041715 | -0.010136 | -0.014742 | 0.015165 | ... | -0.030548 | -0.016873 | 0.034737 | -0.034864 | 0.044394 | -0.005076 | -0.029116 | -0.017710 | 0.004980 | 0.084817 |
| 3 | TEST_003 | -0.018743 | 0.001674 | -0.006065 | 0.012363 | 0.046875 | -0.080868 | -0.005202 | 0.009403 | -0.002780 | ... | 0.004894 | -0.015013 | 0.063273 | -0.048686 | -0.003577 | 0.072423 | -0.018471 | -0.049052 | -0.007638 | 0.069612 |
| 4 | TEST_004 | 0.006434 | -0.012325 | 0.006185 | -0.022150 | 0.097693 | -0.030816 | 0.037679 | 0.080472 | -0.027198 | ... | 0.005342 | 0.011142 | 0.031304 | 0.003474 | -0.014165 | -0.017588 | 0.016631 | 0.027103 | 0.017692 | 0.066538 |
5 rows × 513 columns
# 리더보드 제출을 위한 csv파일 생성
submit.to_csv('/content/drive/MyDrive/content/result/RAG_6.csv', index=False)
DACON 리더보드 확인
566팀 중 59위

이번 튜토리얼에서는 colab에서 무료로 제공해주는 GPU(T4)를 사용하여 LLM QA 시스템을 만들어 보았습니다.
또한, 모델 양자화와 RAG를 결합한다면 높은 성능의 GPU 없이도 원하는 NLP AI 모델을 만들 수 있다는 것을 확인할 수 있었습니다.
References
-
Ko-PlatYi-6B (Ko-PlatYi-6B LLM Model)
-
Komodo_6B_v3.0.0 (TeamUNIVA/Komodo_6B_v3.0.0 LLM Model)
-
Ko-LLM Leaderboard (Ko-LLM Leaderboard)
-
HuggingFace Embedding Leaderboard (Embedding Leaderboard)
-
bge-base-en-v1.5 (Embedding Model)
-
ko-sbert-nli(Embedding Model)
-
LangChain (R.A.G)
