DACON: NLP(자연어 처리) 기반의 QA(질문-응답) 시스템 AI 모델 개발
Dacon Summary
본 대회의 과제는 도배 하자와 관련된 깊이 있는 질의응답 처리 능력을 갖춘 AI 모델을 개발하는 것입니다.
베이스라인에서는 제공된 학습 데이터셋으로부터 질문-답변 쌍을 재구성한 후,
전처리하여 KoGPT2 모델을 Fine-tuning하여 AI 모델을 학습하고 평가 데이터셋으로부터 추론하는 과정을 담고 있습니다.
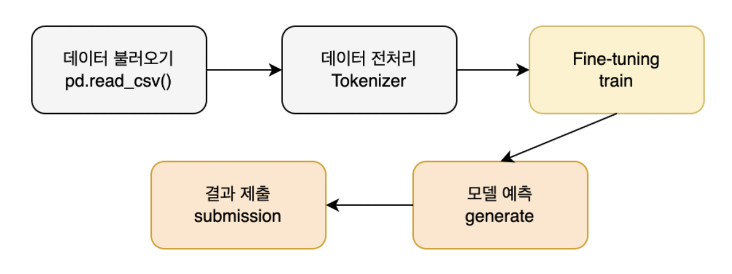
Baseline Modeling Process
본 베이스라인에서는 다음과 같은 프로세스를 따릅니다.
Import
import pandas as pd
import numpy as np
import torch
from transformers import GPT2LMHeadModel, PreTrainedTokenizerFast, AdamW
from tqdm import tqdm
/Users/ghingtae/anaconda3/lib/python3.11/site-packages/transformers/utils/generic.py:260: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node(
# CUDA 사용 가능 여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
Using device: cpu
Data Preprocessing
# 데이터 로드
data = pd.read_csv('./data/train.csv')
# 토크나이저 로드
tokenizer = PreTrainedTokenizerFast.from_pretrained('skt/kogpt2-base-v2', eos_token='</s>')
# 데이터 포맷팅 및 토크나이징
formatted_data = []
for _, row in tqdm(data.iterrows()):
for q_col in ['질문_1', '질문_2']:
for a_col in ['답변_1', '답변_2', '답변_3', '답변_4', '답변_5']:
# 질문과 답변 쌍을 </s> token으로 연결
input_text = row[q_col] + tokenizer.eos_token + row[a_col]
input_ids = tokenizer.encode(input_text, return_tensors='pt')
formatted_data.append(input_ids)
print('Done.')
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization. The tokenizer class you load from this checkpoint is 'GPT2Tokenizer'. The class this function is called from is 'PreTrainedTokenizerFast'. 644it [00:00, 855.53it/s]
Done.
-
PreTrainedTokenizerFast를 활용하여 텍스트 데이터의 수치화를 진행합니다.딥러닝 모델은 수치만을 입력으로 받을 수 있지만, 제공된 데이터는 자연어(텍스트)로 구성되어 있기 때문입니다.
토크나이저는 이런 자연어를 모델이 이해할 수 있도록 수치화 하는 기능을 수행합니다. -
.from_pretrained를 통해 해당 모델의 토크나이저를 호출합니다.KoGPT2 모델을 활용할 예정입니다.
-
eos_token를 설정합니다.질문과 답변의 구분을 할 수 있는 것을 설정합니다.
end od sentence를 뜻합니다. -
.encode를 통해 데이터 수치화 진행합니다.텍스트 데이터의 수치화를 진행합니다.
-
formatted_data토크나이저를 통해 질문-답변 쌍을 수치화 후 저장합니다.
Model Fine-tuning
KoGPT2 모델은 한국어 이해 능력과 표현 능력을 갖추고 있지만, 도배 하자 도메인에 대한 지식은 부족합니다.
따라서, 이미 학습된 모델에게 도배 하자 데이터를 추가로 학습시킬 필요가 있습니다.
이런 절차를 Fine-tuning이라고 부릅니다.
본 베이스라인에서 사용하는 모델은 KoGPT2입니다. 해당 모델에 대한 설명은 다음과 같습니다.
KoGPT2
GPT2는 Transformer 구조의 Decoder 부분을 활용하여 구성된 모델입니다.
이런 GPT2는 주어진 텍스트의 다음 단어를 잘 예측하고, 텍스트를 생성하는 것에 특화되어 있습니다.
KoGPT2는 이런 GPT2 모델의 특성을 살리면서, 부족한 한국어 성능을 극복하기 위해 대량의 한글 텍스트로 학습된 언어모델입니다.

본 베이스라인에서는 KoGPT2 모델을 질문-답변 쌍으로 학습시켜,
모델이 질문을 받을 경우 이에 대해서 다음에 나올 텍스트인 답변을 출력하게 하는 형식으로 질의응답이 가능하게 설계했습니다.
# 모델 로드
model = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
model.to(device) # 모델을 CPU단으로 이동
# 모델 학습 하이퍼파라미터(Hyperparameter) 세팅
# 실제 필요에 따라 조정하세요.
CFG = {
'LR' : 2e-5, # Learning Rate (5e-5, 4e-5, 3e-5, 2e-5, 1e-5)
'EPOCHS' : 10, # 학습 Epoch
}
# 모델 학습 설정
optimizer = AdamW(model.parameters(), lr=CFG['LR'])
model.train()
# 모델 학습
for epoch in range(CFG['EPOCHS']):
total_loss = 0
progress_bar = tqdm(enumerate(formatted_data), total=len(formatted_data))
for batch_idx, batch in progress_bar:
# 데이터를 CPU단으로 이동
batch = batch.to(device)
outputs = model(batch, labels=batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
# 진행률 표시줄에 평균 손실 업데이트
progress_bar.set_description(f"Epoch {epoch+1} - Avg Loss: {total_loss / (batch_idx+1):.4f}")
# 에폭의 평균 손실을 출력
print(f"Epoch {epoch+1}/{CFG['EPOCHS']}, Average Loss: {total_loss / len(formatted_data)}")
# 모델 저장
model.save_pretrained("./model/cpu/hansoldeco-kogpt2")
tokenizer.save_pretrained("./model/cpu/hansoldeco-kogpt2")
/Users/ghingtae/anaconda3/lib/python3.11/site-packages/transformers/optimization.py:411: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning warnings.warn( Epoch 1 - Avg Loss: 2.8435: 100%|██████████| 6440/6440 [30:58<00:00, 3.47it/s]
Epoch 1/10, Average Loss: 2.843499136887352
Epoch 2 - Avg Loss: 1.7486: 100%|██████████| 6440/6440 [31:10<00:00, 3.44it/s]
Epoch 2/10, Average Loss: 1.7486186316942576
Epoch 3 - Avg Loss: 1.1252: 100%|██████████| 6440/6440 [31:41<00:00, 3.39it/s]
Epoch 3/10, Average Loss: 1.1252167138889988
Epoch 4 - Avg Loss: 0.7630: 100%|██████████| 6440/6440 [31:12<00:00, 3.44it/s]
Epoch 4/10, Average Loss: 0.7629801028853526
Epoch 5 - Avg Loss: 0.5382: 100%|██████████| 6440/6440 [31:43<00:00, 3.38it/s]
Epoch 5/10, Average Loss: 0.5382439056365108
Epoch 6 - Avg Loss: 0.4010: 100%|██████████| 6440/6440 [31:32<00:00, 3.40it/s]
Epoch 6/10, Average Loss: 0.40098250961185705
Epoch 7 - Avg Loss: 0.3160: 100%|██████████| 6440/6440 [31:03<00:00, 3.45it/s]
Epoch 7/10, Average Loss: 0.3160299617010429
Epoch 8 - Avg Loss: 0.2649: 100%|██████████| 6440/6440 [31:27<00:00, 3.41it/s]
Epoch 8/10, Average Loss: 0.26486877329497144
Epoch 9 - Avg Loss: 0.2293: 100%|██████████| 6440/6440 [31:24<00:00, 3.42it/s]
Epoch 9/10, Average Loss: 0.2292707207676324
Epoch 10 - Avg Loss: 0.2054: 100%|██████████| 6440/6440 [31:47<00:00, 3.38it/s]
Epoch 10/10, Average Loss: 0.20538172502568142
('./model/cpu/hansoldeco-kogpt2/tokenizer_config.json',
'./model/cpu/hansoldeco-kogpt2/special_tokens_map.json',
'./model/cpu/hansoldeco-kogpt2/tokenizer.json')
-
GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')사전 학습된 KoGPT2 모델을 불러옵니다.
-
Hyperparameter값을 설정합니다.LR(Learning Rate): 학습 속도를 결정합니다.
EPOCHS: 학습을 몇 번 반복할지 결정합니다. -
optimizer모델 최적화 알고리즙을 설정합니다.
본 베이스라인에서는 AdamW로 설정했습니다.AdamW는 과적합 방지와 일반화 성능 향상에 우수합니다.
-
save_pretrainedFine-tuning이 완료된 모델의 weight를 저장합니다.
모델과 토크나이저를 저장할 수 있습니다.
Model Inference
# 저장된 Fine-tuned 모델과 토크나이저 불러오기
model_dir = "./model/cpu/hansoldeco-kogpt2"
model = GPT2LMHeadModel.from_pretrained(model_dir)
model.to(device)
tokenizer = PreTrainedTokenizerFast.from_pretrained(model_dir)
# Inference를 위한 test.csv 파일 로드
test = pd.read_csv('./data/test.csv')
# test.csv의 '질문'에 대한 '답변'을 저장할 리스트
preds = []
# '질문' 컬럼의 각 질문에 대해 답변 생성
for test_question in tqdm(test['질문']):
# 입력 텍스트를 토큰화하고 모델 입력 형태로 변환
input_ids = tokenizer.encode(test_question + tokenizer.eos_token, return_tensors='pt')
# 답변 생성
output_sequences = model.generate(
input_ids=input_ids.to(device),
max_length=300,
temperature=0.9,
top_k=1,
top_p=0.9,
repetition_penalty=1.2,
do_sample=True,
num_return_sequences=1
)
# 생성된 텍스트(답변) 저장
for generated_sequence in output_sequences:
full_text = tokenizer.decode(generated_sequence, skip_special_tokens=False)
# 질문과 답변의 사이를 나타내는 eos_token (</s>)를 찾아, 이후부터 출력
answer_start = full_text.find(tokenizer.eos_token) + len(tokenizer.eos_token)
answer_only = full_text[answer_start:].strip()
answer_only = answer_only.replace('\n', ' ')
preds.append(answer_only)
100%|██████████| 130/130 [06:03<00:00, 2.79s/it]
-
.from_pretrained앞서 저장한 모델과 토크나이저를 불러옵니다.
-
encode테스트 데이터에서 제공되는 질문과 eos_token을 합쳐 input_ids를 구상하고 수치화합니다.
이것은 모델에게 질문 부분만을 입력한 것입니다. -
generateinput_ids에 대한 답변을 생성합니다.
- max_length: 생성될 텍스트의 최대 길이입니다.
- temperature: 생성 텍스트의 다양성을 제어하는 하이퍼 파라미터입니다.(값이 커질수록 다양한 텍스트 생성)
- top_k: 토큰을 생성하는 각 단계에서 고려할 토큰 후보의 수입니다.(값이 커질수록 고려하는 토큰 수가 많아져 다양한 텍스트 생성)
- top_p: 토큰을 생성하는 단계에서 누적확률합이 p값 이하인 토큰들을 후보로 삼는 방식입니다.(값이 커질수록 고려하는 토큰 수가 많아져 다양한 텍스트 생성)
- repetition_penalty: 반복되는 단어나 구절에 대해서 부과되는 패널티입니다.(해당 값이 1보다 클 경우 모델이 반복을 피하도록 유도)
- do_sample=True: 토큰을 생성하는 단계에서 확률적 샘플링을 수행합니다.
- num_return_sequences: 생성할 시퀀스의 수입니다.
-
decode사람이 인식하는 텍스트로 변환합니다.
skip_special_token=False는 eos_token이 출력에서 유지되도록 합니다.해당 과정을 통해 모델이 생성한 텍스트 중 답변 부분만을 구분 가능합니다.
Submission
# Test 데이터셋의 모든 질의에 대한 답변으로부터 512 차원의 Embedding Vector 추출
# 평가를 위한 Embedding Vector 추출에 활용하는 모델은 'distiluse-base-multilingual-cased-v1' 이므로 반드시 확인해주세요.
from sentence_transformers import SentenceTransformer # SentenceTransformer Version 2.2.2
# Embedding Vector 추출에 활용할 모델(distiluse-base-multilingual-cased-v1) 불러오기
model = SentenceTransformer('distiluse-base-multilingual-cased-v1')
# 생성한 모든 응답(답변)으로부터 Embedding Vector 추출
pred_embeddings = model.encode(preds)
pred_embeddings.shape
Downloading modules.json: 0%| | 0.00/341 [00:00<?, ?B/s]
Downloading (…)ce_transformers.json: 0%| | 0.00/122 [00:00<?, ?B/s]
Downloading README.md: 0%| | 0.00/2.45k [00:00<?, ?B/s]
Downloading (…)nce_bert_config.json: 0%| | 0.00/53.0 [00:00<?, ?B/s]
Downloading config.json: 0%| | 0.00/556 [00:00<?, ?B/s]
Downloading pytorch_model.bin: 0%| | 0.00/539M [00:00<?, ?B/s]
Downloading tokenizer_config.json: 0%| | 0.00/452 [00:00<?, ?B/s]
Downloading vocab.txt: 0%| | 0.00/996k [00:00<?, ?B/s]
Downloading tokenizer.json: 0%| | 0.00/1.96M [00:00<?, ?B/s]
Downloading (…)cial_tokens_map.json: 0%| | 0.00/112 [00:00<?, ?B/s]
Downloading 1_Pooling/config.json: 0%| | 0.00/190 [00:00<?, ?B/s]
Downloading 2_Dense/config.json: 0%| | 0.00/114 [00:00<?, ?B/s]
Downloading pytorch_model.bin: 0%| | 0.00/1.58M [00:00<?, ?B/s]
(130, 512)
Submission은 Dacon 참가자분들의 답변이 Dacon의 리더보드 시스템에 맞도록 제출물을 변환하는 과정입니다.
본 대회에서는 답변과 정답을 distiluse-base-multilingual-cased-v1모델을 활용하여 512 차원의 임베딩 벡터로 수치화합니다.
submit = pd.read_csv('./data/sample_submission.csv')
# 제출 양식 파일(sample_submission.csv)을 활용하여 Embedding Vector로 변환한 결과를 삽입
submit.iloc[:,1:] = pred_embeddings
submit.head()
| id | vec_0 | vec_1 | vec_2 | vec_3 | vec_4 | vec_5 | vec_6 | vec_7 | vec_8 | ... | vec_502 | vec_503 | vec_504 | vec_505 | vec_506 | vec_507 | vec_508 | vec_509 | vec_510 | vec_511 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | TEST_000 | 0.027340 | 0.061596 | -0.025882 | -0.007046 | 0.106774 | -0.004059 | -0.000069 | 0.036387 | 0.037929 | ... | -0.000998 | -0.057284 | 0.019608 | -0.036453 | -0.005372 | 0.046832 | 0.014650 | -0.035521 | -0.015767 | 0.049623 |
| 1 | TEST_001 | -0.020574 | 0.020437 | 0.014370 | 0.004303 | 0.130412 | -0.003798 | 0.012226 | -0.010731 | 0.018440 | ... | -0.047342 | -0.003164 | 0.005325 | -0.042955 | -0.024845 | 0.034305 | -0.008815 | -0.033210 | 0.018155 | 0.070663 |
| 2 | TEST_002 | -0.007324 | 0.005959 | -0.049301 | -0.009871 | 0.122781 | -0.013124 | 0.021922 | 0.019223 | 0.068486 | ... | -0.007393 | -0.009298 | 0.046817 | 0.003442 | -0.022947 | 0.007397 | 0.042711 | -0.032420 | -0.045406 | 0.045719 |
| 3 | TEST_003 | -0.008537 | 0.017302 | -0.014496 | 0.023185 | 0.077229 | -0.031583 | -0.068986 | 0.037647 | 0.020204 | ... | -0.028376 | -0.007717 | 0.068868 | -0.042251 | 0.031930 | 0.052879 | -0.001870 | -0.004468 | -0.038466 | 0.049311 |
| 4 | TEST_004 | -0.028175 | -0.029158 | 0.008954 | 0.002002 | 0.122598 | -0.022691 | 0.016108 | 0.072007 | -0.008675 | ... | 0.020321 | -0.010479 | 0.060179 | -0.023746 | -0.028497 | 0.009646 | 0.031331 | -0.015341 | 0.006441 | 0.090920 |
5 rows × 513 columns
# 리더보드 제출을 위한 csv파일 생성
submit.to_csv('./result/cpu_submit_epochs_10_lr_2e-5.csv', index=False)
References
- Dacon(도배 하자 AI 모델 개발)
